Last night, Women in Technology hosted an amazing panel on Big Data for their monthly WIT.Connect. Carol Hayes (Navy Federal Credit Union), Carrie Cordero (Georgetown University), Kim Garner (Neuster Advisory Services Group), Rashmi Mathur (IBM Global Business Services), and Stacey Halota (Graham Holdings Company) joined moderator, Susan Gibson (ODNI) for a discussion on the promise and perils of big data. I’ve compiled my notes to share with you.

How Do we Define “Big Data?”
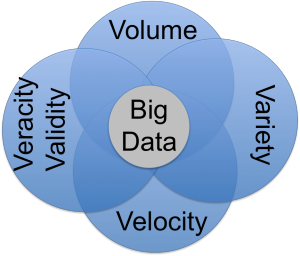
The first stop in the conversation was for the panel to define “big data.” Carol provided us with a brief history of the term, starting with the 1997 use by a group of NASA scientists who primarily were referring to memory & disk space issues. The term was further legitimized in 2014 when it was added to the Merriam-Webster and Oxford dictionaries. This usually requires at least 10 years of use, which alludes to even earlier usage. The panel definition refered to the 4 Vs – volume, variety, velocity & veracity. UC Berkeley researchers are now pushing to include elements of analytics & security.
Does Big Data Live Up to the Hype/Promise?
Much has changed about data over the years. Not only have we seen significant increases in the volumes of data, about 80% of big data is unstructured. Historically, data has been very silo-ed. The struggle for most businesses is figuring out how to use the data to make business decisions. The goal for many is to form a 360 degree view of the customer. Technology is constantly improving to help tackle this challenge. Some of the specific use cases discussed included fraud detection and marketing.
This week’s news brought us word of IBM’s $2.6 billion acquisition of Truven Health. Susan wondered if investments of this size are worth it. Rashmi challenged us to look beyond a single investment and focus on the broader IBM initiative to use data to improve health, and view this acquisition as part of a broader healthcare ecosystem.
On the topic of whether small businesses get left out of the big data conversation, we were reminded that all businesses have very valuable data. Leveraging the data you have with 3rd party data can significantly increase the data value. For small businesses, the bigger challenge tends to be having the internal resources available to drive the business questions and analysis.
What About the Perils? Privacy? Security?
In thinking about the perils, privacy & security of big data, we need to consider it from the point of housing, aggregating & sharing it. Stacey challenged us to answer the question “how much data are we deleting” on a regular basis. She recommends at least having an annual discussion. Before that, you should have already done your data inventory to document what you have & why you have it. Stacey cautions us to be straightforward in thinking about the data you should (or shouldn’t) have. For those working with their client’s data, it all begins with the business question. Once you know what the business goal is, you can decide what data you need. You will need to consider the balance of risk, opportunity and cost.
The collection of data outpaces laws & compliance. This has resulted in a decade of breaches. Protecting information is a governance issues not a technical issues. Governance should drive protection. The enhancements in big data technology has resulted in newer technology including the security measures from the beginning (versus adding it as an afterthought).
It’s agreed that privacy & security issues impact businesses of all sizes. Unfortunately, the smaller organizations take on higher risk as a result of limited structure & longevity. It is much harder for a small business to survive a hit to their reputation breaches can cause. We need to ensure that employees get the education needed to handle data. There should be no distinction between programming and secure programming. Ideally, security becomes so engrained in our business process that it just happens without the need for separate functions.
The panel recommended these 5 actions for getting ahead of compliance issues:
- Review the California recommendations on breach of personal information
- Review the ISO 27001 information security standards
- Establish an Incident Response Plan that outlines point of contacts, forensic partner(s), lawyer, etc
- Have a plan & test it
- there are incident response simulation consultants to assist you
- the general process is to answer a list of questions & receive checklist of legal & custom actions to take
- Share incident information with other companies within the industry
Inherent in housing, aggregating, analyzing and sharing data is risk. How much risk is too much? That will depend on the nature of the organization and the data. IBM has the business group respond to a simple questionnaire that helps drive that assessment during the initial phases of new projects.
While the discussion touched on global compliance for companies, this is currently in a bit of flux at the moment. The Safe Harbor framework that allowed US companies to self-certify that they handle data in a way consistent with the EU requirements was recently challenged. Privacy Shield is the new framework being developed to outline the new requirements. Global companies should be watching these decisions closely.
Where Will the Future Take Us?
- Tell me before it happens – Companies are leveraging historical data to predict the future. More often, companies want to be told what will happen, before it happens. Insights will get crisper as we begin to hone in on relevance.
- Data journalism – the ability to tell stories with data is the wave of the future.
- Natural language and machine learning will make people smarter. It’s all about enablement.
- Threat intelligence – the sharing of information becomes more critical.
- Regulatory compliance – inequality and accountability of government versus private sector will converge.
Any Parting Words of Advice?
The consensus is that big data yields plenty of opportunity. It’s one of the few industries where there are plenty of educational opportunities, and negative unemployment. “Any career with ‘data’ is good.” Be sure to look at degrees and certifications, but those aren’t required. Natural curiosity can nicely lend itself to the human side to data analytics. Deliver “the art of the science.”
One final Afterthought
No good conversation about big data occurs without having a mention of veracity of data. Long before modeling or analysis begins, significant time is spent on ensuring good data exists. Thought and care needs to go into cleaning the data, filling in missing data, ensuring the data makes sense.


 Merriam-Webster defines something as
Merriam-Webster defines something as 
